Elona Shatri
This year’s ISMIR was another peak point for the conference and the Music Information Retrieval (MIR) society. It has been amazing seeing how everything was designed to work toward inclusivity and welcoming of new people to the field of MIR. Except for that, as MIR researchers, we all look forward to ISMIR as the best place to showcase our work.
I will now list some of my favourite papers and activities, talks, initiatives on ISMIR2021.
This paper explores the possibility of using Seq2Seq-based architecture to try to improve transcriptions. It focuses on handwritten sheet music given the challenges such scores present with the ambiguity of the handwriting and the decaying/artefacts on older sheets. The advantage of using such sequences mainly lies in the unavailability of symbol-level bounding box information for training. An image of the score is treated as a sequence of column vectors fed into a CNN based on a VGG19 without the last max-pooling layer. Then the encoder (bidirectional stack of GRUs), generates an intermediate representation comprised as many features vectors as the convolutional networks (CNN).
After the encoder has processed the image, the decoder receives the generated hidden state with the last predicted token in the sequence, producing the next output token until a special end token is produced.
They first trained an LM with the original SM dataset, and then an updated version of the SM comprised of 66% of the tokens present in the HW set. They trained the Seq2Seq classifier with the unmodified SM for 30 epochs and then joined both models and trained them using the Curriculum Learning strategy. Validation and test sets come from the HW set. Parameters settings are shown in the image below.
 For evaluation metrics Symbor Error Rate (SER) was used. Baseline results using BLSTM + CTC are 56% of SER and 31.79% for Seq2Seq.
In conclusion, LM seems to boost performance for handwritten sheet music recognition with the existing evaluation. It is, however hard to tell how these models are keeping the structure and the musical meaningfulness.
For evaluation metrics Symbor Error Rate (SER) was used. Baseline results using BLSTM + CTC are 56% of SER and 31.79% for Seq2Seq.
In conclusion, LM seems to boost performance for handwritten sheet music recognition with the existing evaluation. It is, however hard to tell how these models are keeping the structure and the musical meaningfulness.
AN EMPIRICAL EVALUATION OF END-TO-END POLYPHONIC OPTICAL MUSIC RECOGNITION
This work aims to provide different formulations on how to tackle end-to-end polyphonic music recognition. They first provide the workflow of creating a polyphonic dataset using MuseScore forum and then formulations for end-to-end polyphonic OMR. These formulations are two different approaches; one considers it a multi-task binary classification while the other treats it as multi-sequence detection. They propose FlagDecoder and RNNDecoder respective to the formulations mentioned above. As for data annotations, they used a minimal symbol set sufficient to represent pitch and rhythm. They did not consider dynamics, ties, tuplets, staccatos, accents and other staff text. The only symbols used are barlines, time signatures, key signatures, clefs, and notes. They used the “advance position” encoding, which adds ‘+’ between sequential occurrences. Individual notes of chords are ordered from bottom to top. They select a subset of the MuseScore Polyphonic Dataset (MSPD) with a minimum of 41 symbols length, one measure, two voices, a maximum of 679 symbol length, eight measures, and four voices.
Architecturally speaking, models compared share the same structure of an encoder and decoder. The first one extracts features and give global context of the image encoding to each image slice, and the decoder uses the representations created by the decoder and predict the symbols in the image slices. Encoding/decoding architecture is reused from prior work from Calvo-Zaragoza on monophonic scores.

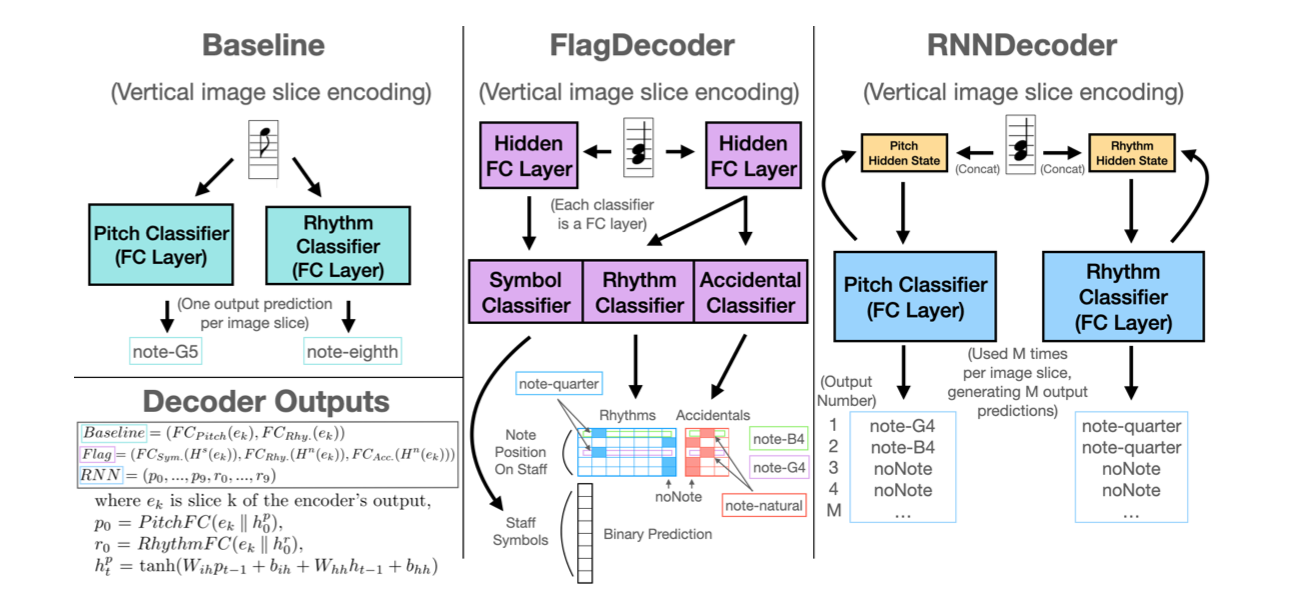 For evaluation metrics they used Pitch and Rhythm Symbol Error Rate (SER).
SER = (I + D + S)/N
While the FlagDecoder slightly improves on the baseline, the RNNDecoder performs twice as well as the baseline. While such approaches are crucial to moving forward to polyphonic music recognition, this work is still very limited in recognising such scores.
For evaluation metrics they used Pitch and Rhythm Symbol Error Rate (SER).
SER = (I + D + S)/N
While the FlagDecoder slightly improves on the baseline, the RNNDecoder performs twice as well as the baseline. While such approaches are crucial to moving forward to polyphonic music recognition, this work is still very limited in recognising such scores.
UNSUPERVISED DOMAIN ADAPTATION FOR DOCUMENT ANALYSIS OF MUSIC SCORE IMAGES
As highlighted in multiple works in OMR, the challenge of the missing annotated data for most of the datasets is very persistent, especially so for supervised learning. As in many other fields, this work tried to explore the possibility of using Domain Adaptation (DA) and transfer knowledge from other domains for which labels are available. They combine DA based on adversarial training with Selectional Auto Encoders to define an unsupervised framework. A framework processes the input images to classify each pixel into a set of possible categories—staff lines, notes, text and background. The architecture has an encoder where data are processed by a series of consecutive convolution and down-sampling layers and a decoder composed of convolutional and up-sampling layers. The output of the SAE will be a probabilistic map with one channel, in which the probability of each pixel belonging to a layer is computed. However, such a framework should be altered when annotated data are missing. This is when DA comes into place, where only domain S needs to have annotations. Using DA then the task is to adapt it to unlabeled data in domain T.
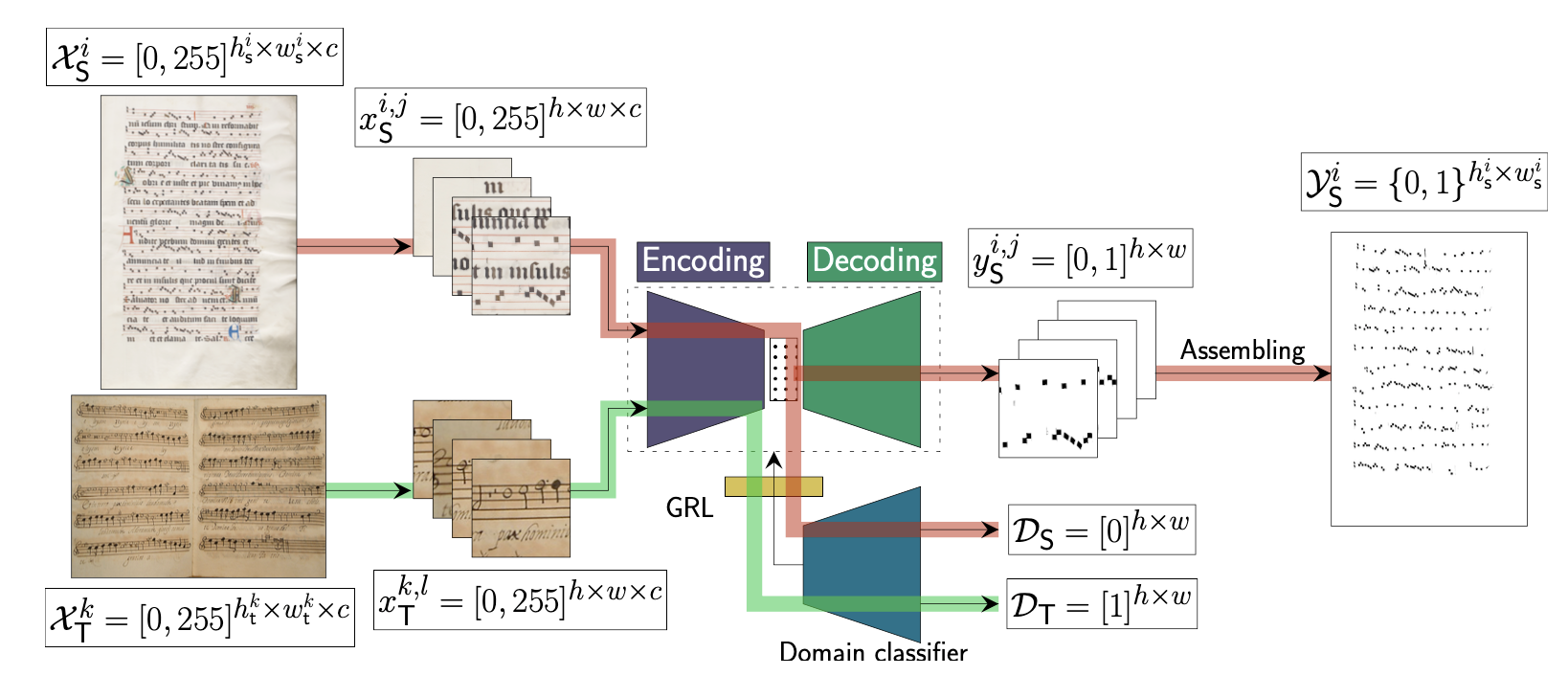 They use the EINSIEDELN, SALZINNES and CAPITAN corporas which are manually labeled. As metrics F1 measure is used, reasoned with the imbalanced distribution of the classes. Adapting from the Neumatic domain to the Mensural domain, DA improves F1 compared to prior work. While transferring knowledge from Mensural (domain S) to Neumatic (T domain), slight improvements and reducing F1 score, depending on the sets used. This could come as domain invariant features are not being extracted by the network depending on the complexity of the datasets.
They use the EINSIEDELN, SALZINNES and CAPITAN corporas which are manually labeled. As metrics F1 measure is used, reasoned with the imbalanced distribution of the classes. Adapting from the Neumatic domain to the Mensural domain, DA improves F1 compared to prior work. While transferring knowledge from Mensural (domain S) to Neumatic (T domain), slight improvements and reducing F1 score, depending on the sets used. This could come as domain invariant features are not being extracted by the network depending on the complexity of the datasets.
ARTIST SIMILARITY WITH GRAPH NEURAL NETWORKS
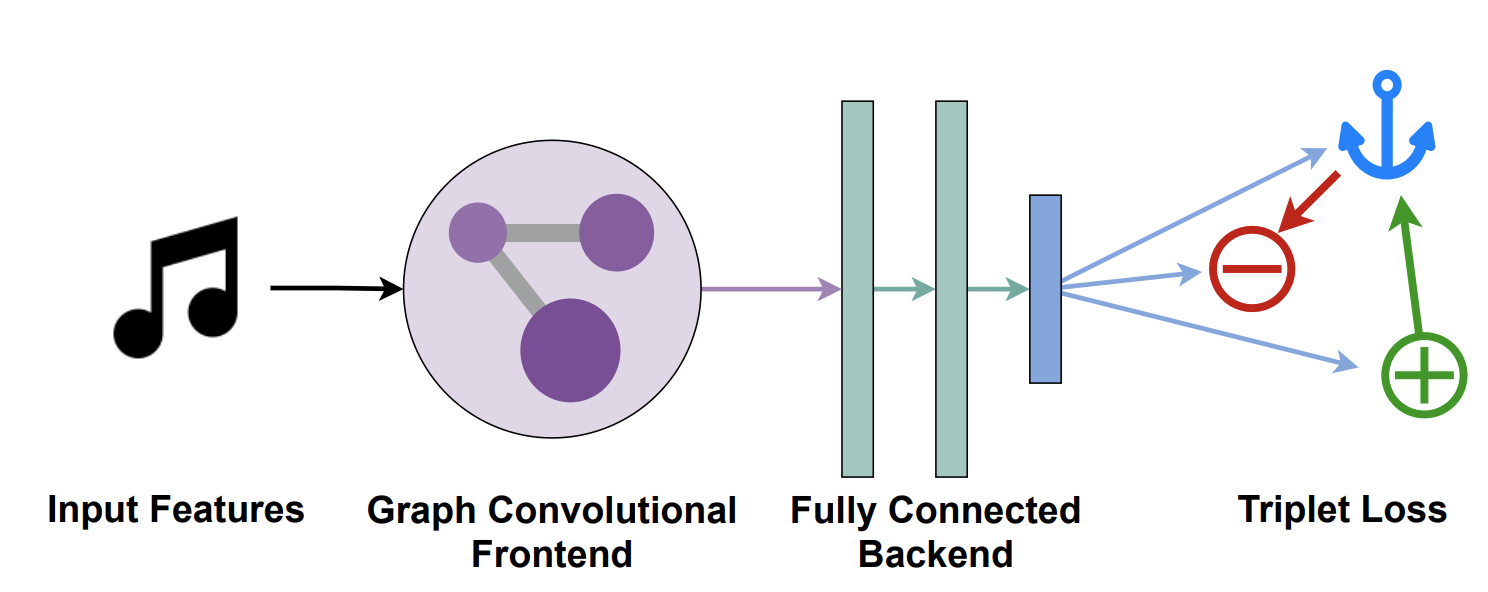
Makes use of Graph Convolutional Neural Networks (GCNN) to add hierarchical relationships to the artist similarity problem using triplet loss. This combines the topology of a graph of artist connections with content features to embed artists into vector space that encodes similarity. They also provide with OLGA dataset that contains 17673 artists with content-based features. Their findings show that such a hybrid approach can be even more effective than high-quality features to understand artist similarity.
New initiatives:
Lab Showcase
A new and fantastic idea for this year’s ISMIR conference was the Lab Showcase chaired by my PhD colleague Lele Liu. This activity featured virtual booths hosted by MIR research labs worldwide; C4DM had its fair share, introducing senior and junior researchers in its booth. Attendees were able to learn about ongoing research, and labs would provide live chat slots to answer questions. This was an excellent opportunity to scout out potential degree programs, expand your network, and get a feel for what current MIR researchers are working on.
Newcomer Initiative Coming to a news conference for the first time can be intimidating and overwhelming. At ISMIR this year, the Newcomer Initiatives Chairs have drawn on the past experiences of the MIR community to provide increased support to newcomers. The initiatives planned for the conference included a pair of special sessions on “Getting the most out of ISMIR 2021”, which follow up on a community survey and blog post on the subject published before the conference. The sessions were hosted by Newcomer Initiatives Chairs Nick Gang (Apple) and myself. Another new initiative was the creation of Newcomer Squads, which connected ISMIR veterans with groups of newcomers to answer questions, give advice, and offer support over the conference week.
Diversity & Inclusion The ISMIR 2021 conference takes a broad view of Diversity and Inclusion (D&I). Under the leadership of the conference D&I Chairs, in collaboration with the organising team at large, ISMIR 2021 offers a variety of initiatives intended to make the conference a positive, welcoming, and supportive environment for a diverse range of presenters and attendees. Notably, this year’s virtual conference format, combined with generous sponsor support, has enabled an unprecedented level of financial support to cover registration and childcare costs. Registration waivers were made available to students, women and other underrepresented minorities in MIR, attendees from low-income countries, presenters in the “New-to-ISMIR” late-breaking/demo track, and unaffiliated attendees. All attendees were additionally eligible to apply for childcare grants. The ISMIR 2021 organisers also worked together to write several blog posts to decrease barriers to participation in the MIR research community, for example, by offering insights into preparing and reviewing scientific submissions. Finally, the ISMIR conference Code of Conduct remains in place for this year’s virtual format.